
2025
2030
60
%



К 2030 году 9 из 10 компаний
будут иметь собственный локальный кластер ИИ.
будут иметь собственный локальный кластер ИИ.
ПРОГНОЗ 2030
это подтверждают тренды суверенности данных, рост стоимости облаков и переход бизнеса на частные LLM.
(⇣)
(⇣)
Локальный ИИ становится новой нормой корпоративной инфраструктуры.
РЕШЕНИЯ И КОНФИГУРАЦИИ
РЕШЕНИЯ И КОНФИГУРА-
ЦИИ
3 уровня
Lite Inference Kit →
Pro LLM Node →
DC–Level Cluster →




01/
Железо:
1× A5000/A6000, 128–256 ГБ RAM
Инфраструктура:
CUDA, Docker, MLflow + MinIO
Интеллект:
Qwen/Llama, базовый RAG
Кому подходит:
компаниям, которым нужен быстрый запуск и документный поиск
Если вам
нужно:
нужно:
RAG, чатбот или внутренний ассистент → выбирайте Lite
Lite Inference Kit
Для RAG,
ассистентов, документооборота
ассистентов, документооборота
02/
Железо:
2–4× RTX 6000 Ada / L40S, 256–512 ГБ RAM
Инфраструктура:
Kubernetes, MLflow + MinIO, мониторинг
Интеллект:
Fine-tuning, создание RAG агентов
Кому подходит:
финтех, промышленность, юрфирмы, IT
Если вам
нужно:
нужно:
обученная на ваших данных модель → выбирайте Pro LLM
Pro LLM Node
Для инференса и обучения моделей до ~14B
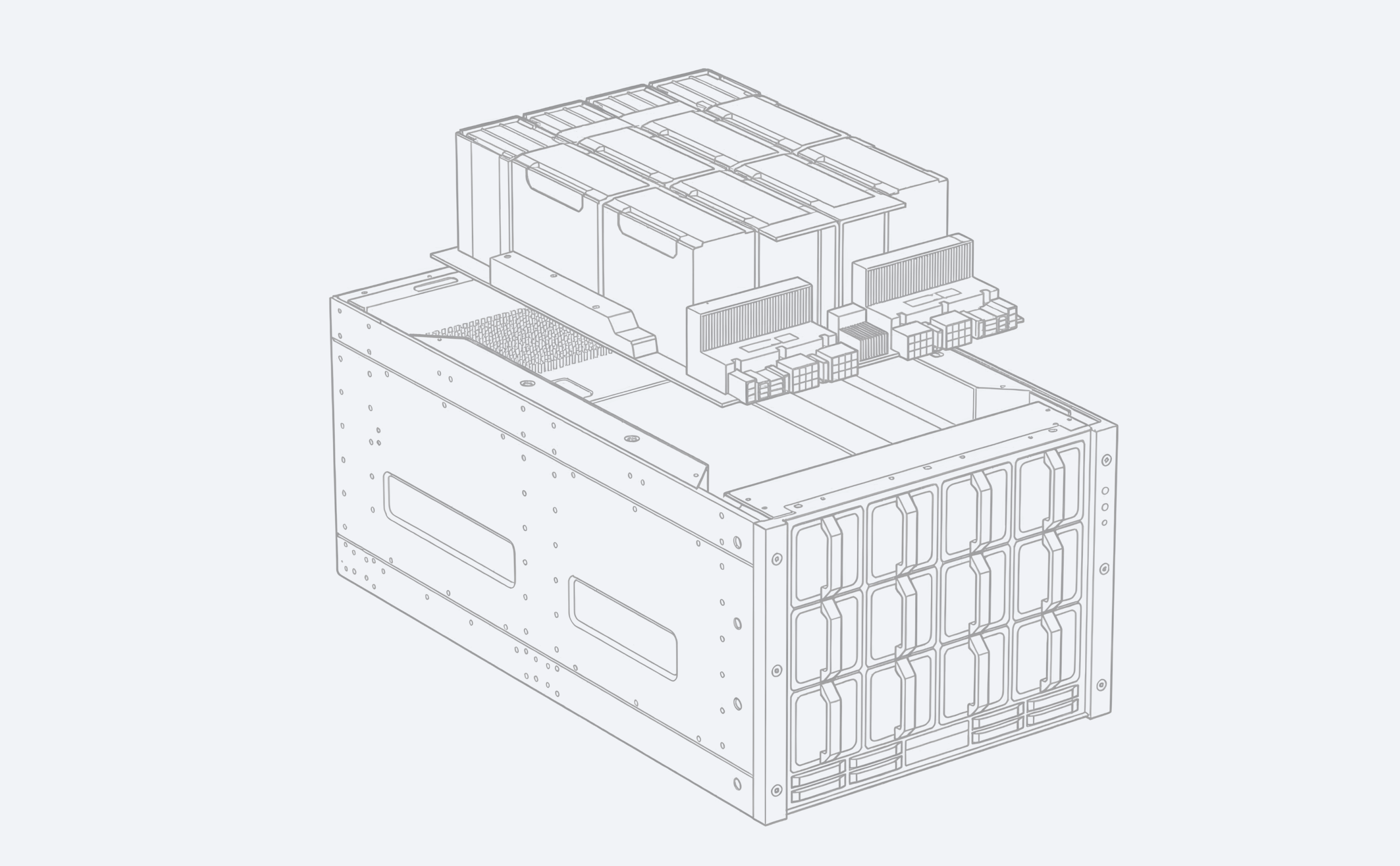
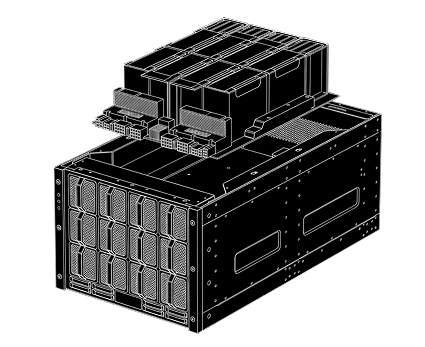
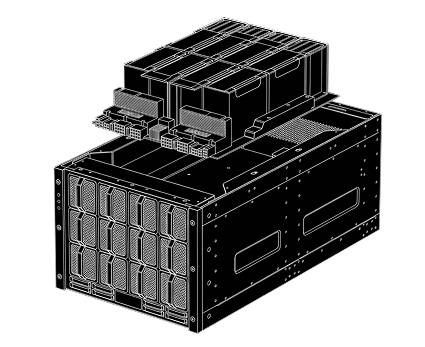
03/
Железо:
4–8× A100/H200, до 2 ТБ RAM
Инфраструктура:
многоузловой Kubernetes, TensorRT-LLM / DeepSpeed
Интеллект:
Ансамбль локальных LLM моделей
Кому подходит:
крупным корпорациям, R&D, банкам
Если вам
нужно:
нужно:
собственная частная LLM → выбирайте Cluster
DC–Level Cluster
Для обучения моделей, частных LLM и тяжёлых ИИ-нагрузок
сравнение
ОБЛАКО VS СОБСТВЕННЫЙ ИИ

параметры:
Облако:
Собственный ИИ:

дорого при постоянных нагрузках

в 3–6 раз дешевле на горизонте 12–18 месяцев


данные уходят на внешние сервера


данные и модели в вашем контуре

зависимость от тарифов и API

полный контроль над архитектурой

очереди, лимиты, падение скорости

стабильная работа 24/7
ограниченная кастомизация

обучение, донастройка, оптимизация
при постоянных нагрузках локальный ИИ становится корпоративным стандартом.
Вывод
При стабильно высоких нагрузках облачные API становятся непредсказуемо дорогими и медленными, тогда как локальный ИИ фиксирует затраты, исключает сетевые задержки и даёт полный контроль над данными.
(⇣)
(⇣)
Именно поэтому компании, вышедшие на промышленный объём использования ИИ, закономерно переходят на собственные инстансы — как раньше переходили с облачных CRM на локальные серверы.

Так же
помогаем
finetuning моделей
Создание RAG-систем
Обучение по созданию и развитию собственного кластера ИИ


Адаптируем готовые языковые модели под ваши уникальные бизнес-задачи и данные, повышая точность и релевантность результатов.
(⇣)
Разрабатываем системы генерации, чтобы ИИ давал ответы только на основе актуальной и проверенной информации.
(⇣)
Обучим вашу команду проектировать, разворачивать и масштабировать собственный вычислительный кластер для задач машинного обучения.
(⇣)


и у вас работает
собственная автономная структура gen ai
собственная автономная структура gen ai
(aI)
Таможня
гарантия
Под ключ
≥14
дней
и у вас работает
собственная автономная
структура gen
ai
собственная автономная
структура gen
ai
наша ЭКСПЕРТИЗА
(⇣)
(⇣)
наш технологический стек


(↗)
Форма для заявки:
© «нейро кластер» 2026. Все права защищены.
Получите консультацию
инженера по ИИ-инфраструктуре
инженера по ИИ-инфраструктуре
Отвечаем в течение 24 часов. Конфиденциально.
Укажите контакты и мы свяжемся свами в ближайшее время